
This is a conversion tool to convert between different character encodings within text documents. It supports nearly all ISO 8859 character sets, all DOS character sets, most important Apple character sets and most of Microsoft Windows character sets (non asian). It is also able to convert between UTF-8, UTF-16 and UTF-16BE (Big Endian), UTF-32. It automatically detects UTF-8, UTF-16, UTF-32 documents. Other supported character sets are AtariST, KOI8-R, KOI8-U, KZ-1048, NeXT, various EBCDIC, total over 60 character sets are supported. The tool is based upon www.unicode.org mapping tables and don't use Windows API for conversion.
Version 2 was completely redesigned and is now a command line based tool which supports same character sets as first version but also supports unlimited file sizes because no in-memory conversion is done. The UTF-8 parser is now less sensible to even malformed source files.
This tool is now freeware! However source code is for sale, if you are interested please contact me. Contact information can be found below.
There are various fields of application. Converting old mainframe computer files (i.e. EBCDIC converted or DOS textfiles) into todays machine (PC) readable formats, converting database dumps into multilanguage compatible UTF-8 format, preparing old single language websites for multi language localization are just three examples.
Because of the specific support of some HTML/XML features like Entities, it is ideally suitable for the conversion of web pages.
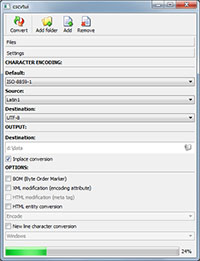
This tool was designed with a view to support a fast conversion of large files. Because of this, wildcard input and recursive conversion of directories are taken for granted. Beside of file processing, this tool also supports console input/output buffer to grab the output of other command line based tools. Communication with (named) pipes are also supported.
*1 Most important character sets are supported.
*2 Following is a list of supported character sets: UTF-16 UTF-16BE UTF-8 UTF-32 UTF-32BE ISO-8859-1 (Latin-1) ISO-8859-2 (Latin-2) ISO-8859-3 (Latin-3) ISO-8859-4 (Latin-4) ISO-8859-5 ISO-8859-6 ISO-8859-7 ISO-8859-8 ISO-8859-9 (Latin-5) ISO-8859-10 (Latin-6) ISO-8859-11 TIS-620 ISO-8859-16 (Latin-10) ISO-8859-13 (Latin-7) ISO-8859-14 (Latin-8) ISO-8859-15 (Latin-9) Windows-874 Windows-1250 Windows-1251 Windows-1252 (Ansi) Windows-1253 Windows-1254 Windows-1255 Windows-1256 Windows-1257 Windows-1258 DOS-437 (CP437) DOS-737 (CP737) DOS-775 (CP775) DOS-850 (CP850) DOS-852 (CP852) DOS-855 (CP855) DOS-857 (CP857) DOS-860 (CP860) DOS-861 (CP861) DOS-862 (CP862) DOS-863 (CP863) DOS-864 (CP864) DOS-865 (CP865) DOS-866 (CP866) DOS-869 (CP869) DOS-874 (CP874) MSMAC-CYRILLIC (CP10007) MSMAC-GREEK (CP10006) MSMAC-ICELAND (CP10079) MSMAC-LATIN2 (CP10029) MSMAC-ROMAN (CP10000) MSMAC-TURKISH (CP10081) Apple-CENTEURO Apple-Roman AtariST KOI8-R KOI8-U DOS-856 KZ-1048 RK1048 (STRK1048-2002) CP1006 (IBM-1006) NeXT openstep nextstep EBCDIC-37 (CP37) EBCDIC-500 (CP500) EBCDIC-875 (CP875) EBCDIC-1026 (CP1026)
*3 CSV file (tab separated) contains 7 columns
| Name | Size | Source CS | Dest. CS | Decoder errors | Encoder errors | Time (ms) |
|---|---|---|---|---|---|---|
| c:\test.txt | 1234 | windows-1252 | utf-8 | 1 | 0 | 30 |
Conversion of 34GB large english wikipedia dump (2012-01-05) from UTF-8 to UTF-16 took about 18 minutes ≈ 2GB/minute, tested on Intel Core I7-2600K on Samsung HD103UJ hard disk. Conversion back from UTF-16 to UTF-8 only took about 15 minutes. Both source and back converted file were exactly same after the conversion.
Conversion of 1GB large file from ISO-8859-15 into UTF-8 took about 15 seconds.
Please subscribe this rss feed if you want to get informed about changes.
Following is a list of some important command line switches:
| Switch | Description |
|---|---|
| /scs /i |
Source character set which can be either one of the single byte character sets (see /listall switch for a complete list), or one of UTF-8, UTF-16, UTF-16BE, UTF-32, UTF-32BE. If auto is specified, the converter tries to auto detect. ISO-8859-15 is default character set if none is detected. The switch /i was introduced in version 2.0.17.1. |
| /dcs /o |
Destination character set. The switch /o was introduced in version 2.0.17.1. |
| /nobom | No BOM (Byte Order Marker) is generated for UTF-8, UTF-16 or UTF-32, BOM will always be removed on input. |
| /eol | End of line character conversion mode. Valid modes are one of dos, unix or mac. DOS uses 0D 0A byte sequence, UNIX uses 0A, MAC uses 0D. |
| /htmlentity | Enables HTML entity encoding or decoding. Valid modes are either enc or dec. On encoding, each convertable characters like &, Ü will be converted into corresponding entities like &, Ü. |
| /xml | Processes XML files and replaces encoding attribute like in <?xml encoding="utf-8"?> header to reflect the new character set change. |
| /r | Includes sub directories on wildcard input (recursive). |
| /s | Be silent, no console output will be generated. If status messages are required, please use /log or /logto switch. |
Conversion of my.txt from iso-8859-1 to utf-8
cscvt.exe my.txt /i iso8859-1 /o utf-8
Conversion of all text files in d:\ and it's sub directories and writing to directory c:\output.
cscvt.exe d:\*.txt /r c:\output
Redirects output of the dir command to cscvt, converting from CP850 to UTF-16 and storing converted data to destination.txt
dir | cscvt.exe \\.\CONIN$ /i cp850 /o utf-16 destination.txt
Conversion of index.xhtml from ISO-8859-1 to UTF-8, each entity like ä will be converted into corresponding UTF-8 character. <?xml?> header will be modified to reflect the new character set changes.
cscvt.exe index.xhtml /xml /htmlentity dec /i iso-8859-1 /o utf-8
To get more information run cscvt with /? argument.
If you need to convert critical data, consider increasing the verbose level with the command line switches /log or /loglevel 2*2. This is important because only then you are able to detect possible conversion errors. The log file contains the character code, and file locations of undetected or malicious UTF-8 character sequences which have been replaced with the replacement character U+FFFD. Some old UTF-8 text files may contain several invalid code sequences for example 5 or 6 byte sequences ("overlong form"), or surrogate pairs coded as two 3 byte codes instead of one 4 byte code.
Current implementation strategy is that the converter always produces valid codes by replacing invalid characters with the U+FFFD replacement character or by skipping some codes. This might not be optimal in all cases. There is an (experimental) command line switch /policy loose to change this behaviour.
| Filter | Strict policy | Loose policy |
|---|---|---|
| UTF-8 | Invalid surrogate pairs, single surrogate code points or 3 byte form will be replaced by U+FFFD. | Invalid surrogate pairs, single surrogate code points or 3 byte form will be converted into corresponding UTF-16 code points. |
| ISO, DOS… | Non convertable characters will be converted into U+FFFF or U+FFFD on input filter and into FF on output filter. | Non convertable characters will be converted into U+DC00…U+DCFF on input filter and into it's corresponding single byte character on output filter. All non convertable input characters will be written to output without change. |
Please note, generated files produced with loose policy may not be UTF-8/UTF-16 compliant.
*2Command line switch /loglevel must be specified after /log or /logto switch if both are used.
None
Please contact me if you need support, if you found a bug or just if you have a suggestion for improvement.
In case of a specific feature request please contact me and I will calculate an individual price.
This is a new experimental text analyzation tool (cscvtanalyzer) to test automatic language and single byte character encoding detection. This tool is based on statistical analysis of text files. Before the character set and language detection can be started, statistical data will be collected. For this purpose, the frequency of characters and combinations of characters in a ‒ preferably large ‒ text file is calculated.
Update: 2013-02-21 (improved, more precise detection)
| Switch | Description |
|---|---|
| /collect | This command will collect data for statistical analysis. Second argument is a text file to be analyzed i.e. /collect file.txt. This command should be used in combination with /charset and /language switch. This file should contain at least 500 KB of language specific texts without too much spaces, numbers or other irrelevant data. This tool is primarily intended to recognize ISO-8859 and Windows character sets. To ignore specific characters, please use /ignore switch. Currently only single byte character sets are supported. |
| /charset | This switch specifies the character encoding of the text file to be analyzed. It will be part of the name of the new generated data file. |
| /language | ISO 3 letter language code of the text file to be analyzed. It will be part of the name of the new generated data file. |
| /threshold | Internal threshold value, is the minimal frequency of specific characters. Default value is 0.003%. This value should not be changed. |
| /ignore | File that contain charcaters to be ignored for analysis. The NULL character should be at the end of the file. |
| Detection | |
| /detect | Analyzes the given text file. Detecting possible languages and character sets. The file should conatin at least 0.5 KB of text for a reliable detection. This switch can be used in combination with /weights switch. |
| /weights | Specifies the weight factors of certain characters or character sequences. It accepts 3 values seperated by comma. Each value will be multiplicated with the frequency of one, two or three character sequences. Sequences of two or more characters are more important than single characters. This value should not be changed. Default value is 1,50,500. |
Currently most important European language/character encoding combinations are supported, mostly ISO-8859's. Feel free to send me additional suggestions.
If detection results are bad you could try to collect your own statistical data. One possible reason could be that your input text file is too small or contains to much mixed languages. You could also try to increase second and third weight factors.
Please also note that there is an overlap of characters in many character sets and thus a different character sets may be recognized as the original. However, this must not be an error as long as the newly recognized character set can represent all characters of the original.
Following command will build stats file by analyzing "german.txt", settings language to "german" with iso-8859-1 character encoding.
cscvtanalyzer /collect german.txt /charset iso-8859-1 /language deu
Following command tries to detect language and charset of the given text file.
cscvtanalyzer /detect blabla.txt
This feature will be integrated into character set conversion tool (cscvt) soon after some more tests. There will be command line switches to restrict the analyzation size of the source file because detection would be very slow if the complete file has to be analyzed.
One problem is still not solved. Some Windows and ISO character sets differ only in a few ‒ often rarely used ‒ characters. It is difficult to distinguish whether the detected character set is an ISO or a Windows character set.